Filebeat + Logstash 使用指南
本节主要介绍数据传输工具Filebeat + Logstash的使用方法:
在开始对接前,您需要先阅读数据规则,在熟悉TA的数据格式与数据规则后,再阅读本指南进行对接。
Filebeat + Logstash上传的数据必须遵循TA的数据格式
注意:Logstash吞吐量低,如果导入大量的历史数据,建议使用 DataX引擎 或者 Logbus工具
1、 Filebeat + Logstash简介
Filebeat + Logstash工具主要用于将日志数据实时地导入到TA后台,监控服务器日志目录下的文件流,当目录下任意日志文件有新数据产生时实时发送至TA后台。
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中。Logstash官网介绍
Filebeat是本地文件的日志数据采集器,可监控日志目录或特定日志文件(tail file),Filebeat 将为您提供一种轻量型方法,用于转发和汇总日志与文件。Filebeat官网介绍
基于Filebeat + Logstash采集流程图如下图所示:
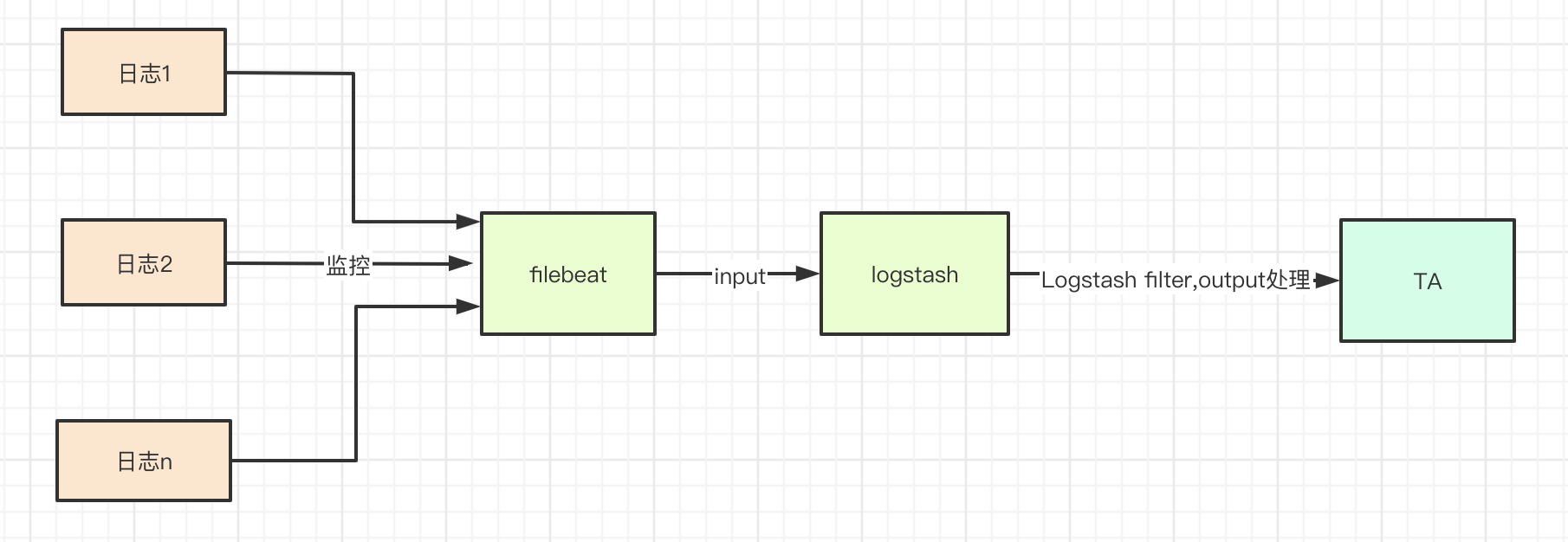
2、Filebeat + Logstash下载与安装
需要注意:Logstash-6.x以上版本, 服务器有JDK环境
2.2 、Logstash下载与安装
参考 Logstash官网安装文档,请选择方式下载
2.3、 logstash-output-thinkingdata 插件
最新版本为:1.0.0
更新时间为:2020-06-09
2.3.1 安装及卸载 logstash-output-thinkingdata 插件
该插件检查数据是否为json数据,打包数据发送到TA 在logstash 目录下执行:
bin/logstash-plugin install logstash-output-thinkingdata
安装需要一点时间,请耐心等待安装成功后,执行:
bin/logstash-plugin list
如果列表中有logstash-output-thinkingdata,则代表安装成功。 其他命令如下展示: 升级插件可以执行:
bin/logstash-plugin update logstash-output-thinkingdata
卸载插件可以执行:
bin/logstash-plugin uninstall logstash-output-thinkingdata
2.3.2 Change Log
v1.0.0 2020/06/09
- 接收Logstash中event传递的message发送到TA中
2.4、 Filebeat下载与安装
参考Filebeat官方安装文档,请选择方式下载
3、Filebeat + Logstash 使用说明
3.1、数据准备
1.首先将需要传输的数据进行ETL转换成TA的数据格式,并写到本地或传输至Kafka集群,如果使用的是Java等服务端SDK的写入Kafka或本地文件的consumer,则数据已经是正确的格式,无需再进行转换。
2.确定上传数据的文件存放的目录,或者Kafka的地址与topic,并配置Filebeat + Logstash的相关配置,Filebeat + Logstash会监控文件目录下的文件变更(监控文件新建或tail已有文件),或者订阅Kafka中的数据。
3.请勿对存放于监控目录下且已经上传的数据日志直接进行重命名,重命名日志相当于新建文件,Filebeat将可能会重新上传这些文件,造成数据重复。3.2 、Logstash配置
3.2.1 Logstash Pipeline 配置
Logstash 支持同时运行多个 Pipeline,各个 Pipeline 之间互不影响,拥有各自独立的输入输出配置,Pipeline 的配置文件位于 config/pipelines.yml 。如果您目前正在使用 Logstash 完成一些其他的日志采集工作,可以在原有的 Logstash 上新增一条 Pipeline 专门负责收集TA的日志数据,并发送至TA 新增的 Pipeline 的配置如下:
# thinkingdata 的管道配置
- pipeline.id: thinkingdata-output
# 如果上传用户属性的核心数设置为1,如果只是上传事件属性可以设置小于等于本机cpu数
pipeline.workers: 1
# 使用的缓冲队列类型
queue.type: persisted
# 使用不同的输入输出配置
path.config: "/home/elk/conf/ta_output.conf"
更多的Pipeline 配置官网: Pipeline
3.2.2 Logstash 输入输出配置
ta_output.conf 参考示例: 注意:这里场景是基于SDK生成的数据的文件,Logstash的输出输入配置
# 使用 beats 作为输入
input {
beats {
port => "5044"
}
}
# 如果不是服务端SDK的生成或者是符合TA格式的数据,需要filter过滤元数据,这里建议是ruby插件过滤,第四模块有案例
#filter {
# if "log4j" in [tags] {
# ruby {
# path => "/home/elk/conf/rb/log4j_filter.rb"
# }
# }
#}
# 使用 thinkingdata 作为输出
output{
thinkingdata {
url => "http://数据采集地址/logbus"
appid =>"您的AppID"
}
}
thinkingdata 参数说明:
| 参数名 | 类型 | 必须 | 默认值 | 说明 |
|---|---|---|---|---|
| url | string | true | 无 | TA数据接收地址 |
| appid | string | true | 无 | 项目的APPID |
| flush_interval_sec | number | false | 2 | 触发flush间隔时间,单位:秒 |
| flush_batch_size | number | false | 500 | 触发flush的json数据,单位:条 |
| compress | number | false | 1 | 压缩数据,0代表不压缩数据,在内网中可设置;1代表gzip压缩,默认gzip压缩 |
| uuid | boolean | false | false | 是否打开UUID开关,用于短时间间隔网络波动可能出现的去重 |
| is_filebeat_status_record | boolean | false | true | 是否开启Filebeat监控日志状态,例如offset,文件名等 |
3.2.3 Logstash 运行配置
Logstash 默认使用 config/logstash.yml 作为运行配置。
pipeline.workers: 1
queue.type: persisted
queue.drain: true
建议
- user_set 即上报用户属性的时候请更改配置 pipeline.workers 的值为 1。当 workers 的值大于 1 时,会导致处理数据的顺序发生变化。track事件可以设置大于1。
- 保证数据的传输不会因为程序的意外终止而丢失请设置 queue.type: persisted,代表 Logstash 使用的缓冲队列类型,这样配置可在重启 Logstash 后继续发送缓冲队列中的数据。 更多数据持久性相关可查看官网 persistent-queues
- 设置 queue.drain 的值为 true ,该配置项会使 Logstash 在正常退出之前将所有缓冲队列中的数据全部发送完毕。 更多详情可查看官网 logstash.yml
3.2.4 Logstash 启动
在Logstash安装目录下 1.直接启动,使用 config/pipelines.yml 作为 Pipeline 配置和运行配置
bin/logstash
2.指定 ta_output.conf 为输入输出配置文件启动 ,会使用 config/logstash.yml 作为运行配置
bin/logstash -f /youpath/ta_output.conf
3.后台启动
nohup bin/logstash -f /youpath/ta_output.conf > /dev/null 2>&1 &
更多启动,可以查看Logstash官方启动文档
3.3、 Filebeat配置
3.3.1 Filebeat 运行配置
Filebeat 读取后端 SDK 日志文件。Filebeat 默认配置文件为:filebeat.yml 。config/filebeat.yml 参考配置如下:
#======================= Filebeat inputs =========================
filebeat.shutdown_timeout: 5s
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/log.*
#- c:\programdata\elasticsearch\logs\*
#------------------------- Logstash output ----------------------------
output.logstash:
# 可填写一个服务器的进程,也可以填写多个服务器上的Logstash进程
hosts: ["ip1:5044","ip2:5044"]
loadbalance: false
shutdown_timeout :Filebeat在关闭之前等待发布者完成发送事件的关闭时间。
paths:指定要监控的日志,目前按照Go语言的glob函数处理,没有对配置目录做递归处理。
hosts: 发送地址为多个 Logstash hosts ,当loadbalance 为false 类似主备功能,true 代表负载均衡
loadbalance: 如果有user_set用户属性上报的情况下不要设置 loadbalance : true , 设置会使用轮询的方 式将数据发送至所有的 Logstash 这很可能导致数据的顺序被打乱。 如果只是导入track事件情况下,可以设置多个Logstash进程,并且可以设置 loadbalance : true。Filebeat 的默认配置为 loadbalance : false
Filebeat资料可查看:Filebeat官方文档
3.3.2 Filebeat 启动
filebeat启动后,查看相关输出信息:
./filebeat -e -c filebeat.yml
后台启动
nohup ./filebeat -c filebeat.yml > /dev/null 2>&1 &
4.案例配置参考
4.1 、filebeat监控不同日志格式的数据配置
单个Filebeat 的 filebeat.xml 可以设置如下,运行内存大概 10 MB 左右, 也可以起多个filebeat进程监控不同的日志格式,具体可以参考官网
#=========================== Filebeat inputs =============================
filebeat.inputs:
- type: log
enabled: true
#监控目录
paths:
- /home/elk/sdk/*/log.*
#给数据打tags,Logstash进行匹配,不用做filter处理
tags: ["sdklog"]
#按特殊字符切分的数据
- type: log
enable: true
paths: /home/txt/split.*
#给数据打tags,Logstash进行匹配,需要filter处理
tags: ["split"]
# log4j接收的数据
- type: log
enable: true
paths: /home/web/logs/*.log
# 需要filter处理
tags: ["log4j"]
# log4j接收的数据
# nginx日志数据
- type: log
enable: true
paths: /home/web/logs/*.log
tags: ["nginx"]
4.2 、Logstash 配置
检测Logstash的配置文件是否错误
bin/logstash -f /home/elk/ta_output.conf --config.test_and_exit
注意:以下脚本所有ruby插件都是基于ruby语法编写而成,如果您对java熟悉,可以使用logbus目录下的自定义解析器
4.2.1 服务端SDK日志
ta_output.conf 可以如下设置
input {
beats {
port => "5044"
}
}
# 使用 thinkingdata 作为输出
output{
thinkingdata {
url => "url"
appid =>"appid"
# compress => 0
# uuid => true
}
}
4.2.2 log4j日志
log4j 格式可以如下设置,根据业务日志情况来设置:
//日志格式
//[%d{yyyy-MM-dd HH:mm:ss.SSS}] 日志符合TA的输入时间,也可以是yyyy-MM-dd HH:mm:ss
//[%level{length=5}] 日志级别,debug、info、warn、error
//[%thread-%tid] 当前线程信息
//[%logger] 当前日志信息所属类全路径
//[%X{hostName}] 当前节点主机名。需要通过MDC来自定义。
//[%X{ip}] 当前节点ip。需要通过MDC来自定义。
//[%X{userId}] 用户登录的唯一ID,可以设置account_id,也可以设定为其他值,TA中要求account_id 和distinct_id不能同时为空,可以设置其他的属性,看业务设置。需要通过MDC来自定义。
//[%X{applicationName}] 当前应用程序名。需要通过MDC来自定义。
//[%F,%L,%C,%M] %F:当前日志信息所属的文件(类)名,%L:日志信息在所属文件中的行号,%C:当前日志所属文件的全类名,%M:当前日志所属的方法名
//[%m] 日志详情
//%ex 异常信息
//%n 换行
<property name="patternLayout">[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%level{length=5}] [%thread-%tid] [%logger] [%X{hostName}] [%X{ip}] [%X{userId}] [%X{applicationName}] [%F,%L,%C,%M] [%m] ## '%ex'%n
</property>
ta_output.conf 配置
input {
beats {
port => "5044"
}
}
filter {
if "log4j" in [tags]{
#也可以进行其他filter数据处理
ruby {
path => "/home/conf/log4j.rb"
}
}
}
# 使用 thinkingdata 作为输出
output{
thinkingdata {
url => "url"
appid =>"appid"
}
}
/home/conf/log4j.rb 脚本如下
# 这里通过参数event可以获取到所有input中的属性
def filter(event)
_message = event.get('message') #message 是你的上传的每条日志
begin
#这里是正则出正确数据的格式,如果是error日志建议单独放在一个文件,错误日志过长没有分析场景,且跨行了
#这里的数据类似这样的格式 _message ="[2020-06-08 23:19:56.003] [INFO] [main-1] [cn.thinkingdata] [x] [123.123.123.123] [x] [x] [StartupInfoLogger.java,50,o)] ## ''"
mess = /\[(.*?)\] \[(.*?)\] \[(.*?)\] \[(.*?)\] \[(.*?)\] \[(.*?)\] \[(.*?)\] \[(.*?)\] \[(.*?)\] ## '(.*?)'/.match(_message)
time = mess[1]
level = mess[2]
thread = mess[3]
class_name_all = mess[4]
event_name = mess[5]
ip = mess[6]
account_id = mess[7]
application_name = mess[8]
other_mess = mess[9]
exp = mess[10]
if event_name.empty? || account_id.empty?
return []
end
properties = {
'level' => level,
'thread' => thread,
'application_name' => application_name,
'class_name_all' => class_name_all,
'other_mess' => other_mess,
'exp' => exp
}
data = {
'#ip' => ip,
'#time' => time,
'#account_id'=>account_id,
'#event_name'=>event_name, #如果是type是track的时候可以用,如果没有#event_name 不用上传
'#type' =>'track', #可以在文件中获取,如果文件中有的话,确认上报数据是否为用户属性或者事件属性
'properties' => properties
}
event.set('message',data.to_json)
return [event]
rescue
# puts _message
puts "数据不符合正则格式"
return [] #不进行上报
end
end
4.2.3 Nginx日志
首先先定义Nginx日志的格式,如果设置为json格式的话
input {
beats {
port => "5044"
}
}
filter {
#如果是同样的格式数据不需要判断tags
if "nginx" in [tags]{
ruby {
path => "/home/conf/nginx.rb"
}
}
}
# 使用 thinkingdata 作为输出
output{
thinkingdata {
url => "url"
appid =>"appid"
}
}
/home/conf/nginx.rb 脚本如下:
require 'date'
def filter(event)
#取出类似日志信息
# {"accessip_list":"124.207.82.22","client_ip":"123.207.82.22","http_host":"203.195.163.239","@timestamp":"2020-06-03T19:47:42+08:00","method":"GET","url":"/urlpath","status":"304","http_referer":"-","body_bytes_sent":"0","request_time":"0.000","user_agent":"s","total_bytes_sent":"180","server_ip":"10.104.137.230"}
logdata= event.get('message')
#解析日志级别和请求时间,并保存到event对象中
#解析json格式日志
#获取日志内容
#转成json对象
logInfoJson=JSON.parse logdata
time = DateTime.parse(logInfoJson['@timestamp']).to_time.localtime.strftime('%Y-%m-%d %H:%M:%S')
url = logInfoJson['url']
account_id = logInfoJson['user_agent']
#event_name
#account_id或者#distinct_id 同时为null时,跳过上报
if url.empty? || url == "/" || account_id.empty?
return []
end
properties = {
"accessip_list" => logInfoJson['accessip_list'],
"http_host"=>logInfoJson['http_host'],
"method" => logInfoJson['method'],
"url"=>logInfoJson['url'],
"status" => logInfoJson['status'].to_i,
"http_referer" => logInfoJson['http_referer'],
"body_bytes_sent" =>logInfoJson['body_bytes_sent'],
"request_time" => logInfoJson['request_time'],
"total_bytes_sent" => logInfoJson['total_bytes_sent'],
"server_ip" => logInfoJson['server_ip'],
}
data = {
'#ip' => logInfoJson['client_ip'],#可以为null
'#time' => time, #不可为null
'#account_id'=>account_id, # account_id 和distinct_id 不可同时为null
'#event_name'=>url, #如果是type是track的时候可以用,如果没有#event_name 不用上传
'#type' =>'track', #可以在文件中获取,如果文件中有的话,确认上报数据是否为用户属性或者事件属性
'properties' => properties
}
event.set('message',data.to_json)
return [event]
end
4.2.4 其他日志
ta_output.conf 配置如下
input {
beats {
port => "5044"
}
}
filter {
if "other" in [tags]{
#也可以进行其他filter数据处理
ruby {
path => "/home/conf/outher.rb"
}
}
}
# 使用 thinkingdata 作为输出
output{
thinkingdata {
url => "url"
appid =>"appid"
}
}
/home/conf/outher.rb 脚本如下:
# def register(params)
# # 这里通过params获取的参数是在logstash文件中通过script_params传入的
# #@message = params["xx"]
# end
def filter(event)
#在这里处理业务数据,如果没有进行grok等一系列处理的情况下,直接在message中获取元数据进行处理
begin
_message = event.get('message') #message 是你的上传的每条日志
#这里处理的log是类似以下的数据
#2020-06-01 22:20:11.222,123455,123.123.123.123,login,nihaoaaaaa,400
time,account_id,ip,event_name,msg,intdata=_message.split(/,/)
#或者通过正则匹配数据,或者json数据,ruby语法解析json即可,可以在这里进行数据处理进行数据上报
#mess = /正则/.match(_message)
#time = mess[1]
#level = mess[2]
#thread = mess[3]
#class_name_all = mess[4]
#event_name = mess[5]
#account_id = mess[6]
#api = mess[7]
properties = {
'msg' => msg,
'int_data' => intdata.to_i #to_i是int类型 ,to_f 是float 类型 ,to_s 是string类型(默认)
}
data = {
'#time' => time,
'#account_id'=>account_id,
'#event_name'=>event_name,
'#ip' => ip,
'#type' =>'track',
'properties' => properties
}
event.set('message',data.to_json)
return [event]
rescue
#如果不想某个数据过去或者出错,这条数据可以返回空,比如account_id 或者 distinct_id 都为null 直接返回[]
return []
end
end